Last Thursday I was lucky enough to visit IBM’s Big Data Crunching Operation behind (amd underneath) the annual Wimbledon Tennis tournament, courtesy of fellow Tuttler Andrew Grill of IBM (who says nepotism never pays) and also courtesy of the knowledgeable and enthusiastic (despite me being the Nth tour guest of the week) Sam Seddon who escorted me through the databunkers.
Now I am far from the first Old Tuttler blogger that Andrew has invited, my colleague David Terrar went last year and Neville Hobson went on the Tuesday last week (here is his post). Thus the “what happens behind the Datascenes at Wimbledon ” is already more than well covered, just look at David’s blog post from last year – to quote:
Sam [Seddon] has a team of around 200 supporting Wimbledon using an impressive array of terminals and technology on site, supplemented by an enormous amount of Cloud compute power from data centres in Amsterdam and the USA. They are providing a service to the All England Lawn Tennis Club to help make Wimbledon the premier sporting event, but in doing so they are serving the audience at the ground, fans around the World, the radio and TV broadcasters of the event, the event sponsors, the Club itself, and even the players directly
David did a good analysis of the overall IBM operations last year, and had some cracking photos – so what can I add to this? Probably the best is to talk about it from the point of view of things I know about in some detail – in this case, high end datacentre infrastructure, real time big data & analytics, and system automation (in this case, Watson)
High End Datacentre Infrastructure
Firstly, from the point of view of datacentre infrastructure, this is a high pressure operation – real time, high visibility, peaky data flow. High embarrassment if things go wrong. Also, the web based systems get quite a few attacks 24/7. And as well as running all the tennis data feeds discussed below, IBM also run the ticket checking and security operations of the whole site.
Secondly, from an Operations & Logistics point of view this is further complicated as the whole setup is also completely transient – for 2 weeks a year the Tournament Tennis circus descends on Wimbledon. The entire IBM system rolls in, the porta-datacentre and its operatives are wheeled into the empty bunkers from locations elsewhere in the world (along with all the TV broadcast trucks, meedja personalities, commentators in their glass boxes, tennis line callers, buckets of strawberries and flagons of Pimms etc etc) – and then two weeks later the whole panjandrum disappears and the whole site is emptied and mothballed again for another year.
This is non trivial stuff, kudos to IBM for making it so seamless!
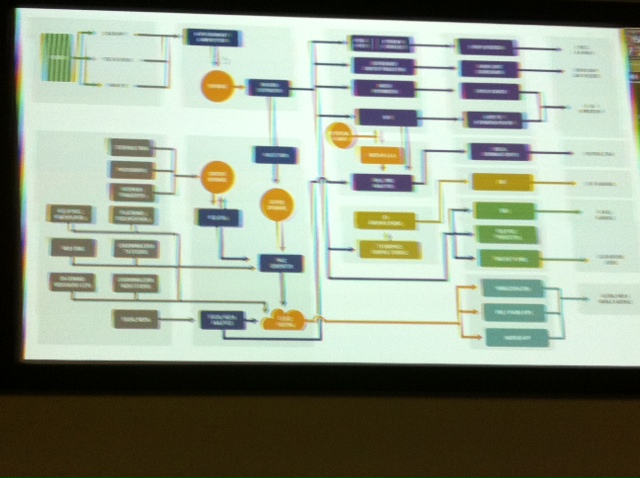
The IBM Dataflow – camera had too much Pimms by then….
Big Data & Real Time Analytics
From a “big data fan” viewpoint there are 3 main data handling operations (see flowchart above, and weep) – in summary::
Player Statistics
Every shot played by every player is captured, not just physically but with rich metadata – tennis experts analyse every shot and record what it was, why it was played, did it work/fail. Interestingly IBM captures data from every major tournament so you can pick up a rich data picture of every player and the permutations of their matched with others.
Added Tennis Metadata
Not only player match stats, but their historical metadata and also Wimblestats are collected – for example, veteran Leighton Hewitt hit his 1500th ace the day I was there, and they can play comparison games with stats back to the 1870’s. Much of this metadata is for the consumption of the output feeds – websites, TV & Radio and social media, to add richness.
Social Media Analysis
The 3rd operation is the monitoring of Twitter feeds off the Gnip firehose. To my readers much of this is familiar ground – find, scrape, focus, process, analyse, use output to inform and focus further coverage etc. (David covered it last year if you’d like more detail) However, there were a few counter-intuitive things I learned:
– Court Prowess and Twitter are loosely linked – Rafa Nadal was the most talked about all player week, despite being an early exit
– Tennis stars endorsing brands is pretty pointless, on Twitter anyway – the online conversation and attention follows the person, not the brand, no matter how many hashtags the PR people throw into the Wimbledome.
– Well heeled Wimbledon fans are by and large not Twitterers, those who can pay to watch live tennis are by and large not (yet) the Generation Who Tweet – but it grows every year
– Increasingly, fairly respected online retailers are clocking onto on the twitter trending #tags and ad-spamming them (Wimbledon is clearly a better class of hashtag)
I was a bit taken aback by the last one, but I guess when you think about it, in media there is a general trend that where porn blazes a trail, advertising soon follows 
To a data modelling/simulation wonk like me this was all fascinating, and I hit Sam with all sorts of “what ifs” but he reminded me that It’s all about understanding the business of tennis – that you have to look at who the customers are, and what they want. I may want to run the Moneyball Crunch of all crunches on the tennis world and create virtual avatars so I can play Bjorn Borg against Rafa Nadal, but realistically the data is required by:
– Media organisations looking to enrich (and pad out….) their commentary teams’ output, especially as the days progress and the early round flood of games subsides
– A “value add” that Wimbledon.com alone can provide the legions of the tennis–nuts from its website, they aim to be the best tournament in the world.
– Coaches/players who want to look at their performance to improve (apparently not all do this, so data-led training has not got to the level many of the big team games – odd in my view given the spoils to the victors involved, but hey….)
Automated Intelligence
‘You know my methods, Watson.’
….said Sherlock Holmes in The Crooked Man (he never said “Elementary, my Dear Watson), and to me this is what is starting to set apart what IBM is doing vs other big iron data operations.
For those who don’t know about Watson, it is a very powerful Machine-Learning system initially focused on natural language processing. It’s key role is Question Answering, so underlying the language processing is are powerful deduction chain algorithms. In short, if you can feed it information and deduction methods, it can form its own hypotheses and reasoning chains This makes it useful for quiz shows (it won at Jeopardy in 2011), medical diagnoses, and – well, tennis among other things.

Data for Watson
Right now it is being taught the basics of Tennis geekdom (What is love? – answer – a score of zero), being force fed Wimbledon tennis history (to draw parallels etc) and is starting to look at the social media chatterflow. But if you look at the data processing going on at Wimbledon, there are a LOT of workflows, methods and deduction chains that are ideal for a natural learning machine learning system.
So when afterwards the IBM people asked me what my main thoughts were from the tour, I told them that in my view, many of their 200 or so operatives here will disappear in the next 5 – 10 years as Watson and other AIs start to take over the rote data processing going here, and then the less rote, and then the really high value add..
And yes, it felt traitorous to say that, sipping Pimms and watching the bright young meedja things gambolling on the grass, but at the end of the day the automation of dataflow & analytics is just the next step in an ongoing process.
Wimbledon is just part of a trend I see everywhere right now, wherever previously unstructured data is being digitised. First comes the rudimentary digitisation of hitherto unstructured data (often from manual or semi manual processes ), then comes the early analytics which creates huge value from the low hanging datafruit, and increasingly we now are starting to see the application of automation, both in data capture (IoT) and analytic reasoning (MI/AI). The future will come one automated data feed and workflow method at a time.
Below – courtside datacapture – how many years till it’s automated?

Automating the Tennis Tournament Production Factory?
Wimbledon makes 70% + of it’s money from selling Media rights for the two weeks of the tournament (and as more and more courts get their own datafeeds this revenue will only increase).
And as all those assets, that span acres of prime London real estate – the main courts, the techie bunkers and media circus rings, the player palaces, the buildings for the huge catering and logistics operations – all largely lie fallow for 50 weeks of the year, Wimbledon will always need to maximise income and minimise costs from those 2 weeks a year.
Thus they will inevitably be pushed into the economics of ongoing automation of Tennis Tournament production. The need to both reduce operating costs and produce ever more value-add from the datafeeds is probably inevitable. The competition for media $ will only intensify, other tournament operations will up their value add year by year. So that means more and more AI for the data handling and analytics tasks, to produce more value add for Wimbledon and its customers.
Unless, unless…..the unquantifiable human input can be shown to make the critical difference between an experience that will delight, versus one that is merely artificially inserted.
Maybe automation will have it’s limitations, we may not like a smart Watson, but instead prefer a nice-but-slightly-dim Watson to our human Holmes – quoth Mr Holmes:
A confederate who foresees your conclusions and course of action is always dangerous, but one to whom each development comes as a perpetual surprise, and to whom the future is always a closed book, is indeed an ideal helpmate.
We shall see. I’d place my money on Smart Watson though….